When Your AI Agents Forget The Time
Posted: July 11, 2026 Filed under: Personal, smallbizai.au | Tags: openclaw, smallbizai.au Leave a commentAt 7am on Saturday, July 11, our AI editor sent a CRITICAL alert. Thirty-nine posts scheduled outside the 9am–noon Melbourne window. Midnight batches. Posts at 1am, 2am. The queue was apparently in pieces.
It wasn’t. Every one of those 39 posts was correctly scheduled in a valid morning slot. The editor was reading UTC timestamps from the WordPress API and treating them as Melbourne time. A post at 9am AEST is stored as T23:00:00 UTC, the previous night. Seen through the wrong lens, the whole queue looked like a disaster.
Thirty-nine false alarms. CRITICAL. Fix immediately.
We fixed the editor’s instructions. The report had already landed.
This keeps happening
That morning’s audit also found two posts that were genuinely wrong. Two Zero Dollar Fix posts in September, actually scheduled at 1:30am AEST. Not UTC confusion, the slot calculator had written T01:30:00 local. We moved them to 11:30am while we were in there. One audit, two different classes of bug, fixed the same morning.
That’s the pattern. Time and dates are where things quietly go wrong, and they go wrong in ways that look similar on the surface but have completely different causes.
The UTC incident was a tool failure: the right data, read wrong. The 1:30am slots were a data failure: the data itself was wrong. Both showed up as “posts scheduled at the wrong time.” Only one of them was.
The rule that had to be written down
There’s a standing instruction in our system now: before writing any date into a JSON file, a cron, or a filename, run a clock check. Do not calculate. Do not reason from context. Check.
That rule exists because we got it wrong enough times for it to need writing down.
An AI agent calculating “next Monday” from session context instead of calling the actual clock will get it wrong. Not every time, often enough. The agent “knows” it’s Thursday. It knows the post is going out “next week.” It does the arithmetic. The arithmetic is right. The starting date was wrong by two days because the session context was stale.
Wrong dates in state files cascade. A post scheduled for the wrong week. A cron set to fire on the wrong day. A content queue entry dated a week ahead of where it should be. None of it obvious until something breaks downstream.
The migration that broke time
During our migration from AWS in April, two Sunday Specials published on the same day, off-schedule and out of sequence. The automation assumed a clean timeline. Migration weekends don’t have clean timelines.
It took weeks to properly resolve the numbering confusion in the series. Not because the system failed, it hadn’t. Because the assumption failed. The system assumed that time would behave. Migration weekend time does not behave.
Dead links with a clean paper trail
We have another rule: always fetch the real post URL from the WordPress API using the post ID. Never construct a URL from the title.
That rule exists because we did it wrong twice. Titles get truncated. Words get dropped. Slugs don’t always match what you’d expect from the title. Our social sharing log had two entries pointing at URLs that didn’t exist. Posts “confirmed as shared” to audiences that clicked dead links.
The system had logged success. The links were 404s.
What we changed
The clock check before any date write is now explicit in the agent instructions, not implied. UTC-to-AEST conversion is baked into every script that touches timestamps, it’s not something we expect the reading tool to handle correctly by default. The editor’s timezone note moved from the bottom of its config doc to the top, in capitals, before anything else.
The URL rule is the same pattern: the fix was to stop trusting inference and start requiring a verified lookup. The post ID goes in. The canonical URL comes out. No guessing.
The Telstra footnote
On July 8, 2026, Telstra’s SyncServer S300 reset the network clock and knocked Triple Zero offline for parts of the country. The device stopped being manufactured around 2016 and had been flagged for replacement for years. A firmware patch that would have cost less than $30,000 was available. They knew. The scale is different from what we’re dealing with here, obviously. But the failure mode is the same: a system that assumed it knew what time it was, and didn’t check.
Questions worth asking about your own setup
Is your payroll software set to Melbourne time or UTC? If a shift worker clocks in at midnight and your system stores timestamps in UTC, someone’s getting paid for a shift that looks like it happened yesterday.
Does your booking tool handle the AEST/AEDT transition in October and April? That one-hour shift catches systems that hardcode UTC+10 instead of using a proper timezone library.
If your AI assistant tells you “today is Thursday”, does it actually check, or does it reason from the last thing it was told?
These aren’t hypothetical edge cases. They’re the class of failure that looks like a data problem, a scheduling problem, or a person problem, until you trace it back to a system that guessed at the time instead of measuring it.
Still at it
We’re still making these mistakes. The UTC/AEST incident was recent. The slot calculator error was sitting in the queue for weeks before the audit found it. The difference now is that we write them down, fix the rule, and move on.
That’s the whole log. No tidy conclusion. The next one will probably be something we haven’t thought of yet.
Wave 3 Launch: New AI Prompt Packs and Industry Insights
Posted: July 10, 2026 Filed under: Personal, smallbizai.au | Tags: artificial-intelligence, openclaw, smallbizai.au, technology Leave a commentWave 3 is live. Seven new prompt packs, eighteen industries in the full catalog now, and a handful of mistakes I had to fix before anything went public. This post covers how I choose industries, how the publishing machine works, what went wrong, and where things go from here.
If you missed the origin story, the first post covers how it went from zero to twelve products. This one picks up from there.
How I pick industries
It starts with Bing AI citation data. Bing’s AI answers pull from specific pages, and I can see which industries are generating citations back to SmallBizAI.au. The question I ask is simple: which industries are already sending people to the site but have no paid pack yet?
From there, it’s a content depth check. Each pack needs 50 real, usable prompts across five sections. That means I need enough posts in that category to actually draw from. If the content base isn’t there, the pack isn’t there. I’m not writing prompts into a vacuum.
Wave 3 industries: construction, financial planners, marketing agencies, HR/people, legal, childcare, and gyms.
Some were obvious. Legal had a full series of posts. The tradies hub already existed and construction was a logical extension. Marketing agencies had strong category depth. Others were less expected. Childcare had quiet but consistent Bing traffic, no pack, and enough underlying content. That was enough. Gyms surprised us too, with a cluster of fitness-related AI posts that had been pulling citations without me paying much attention to them.

The rule: if Bing is already sending people to us for an industry, a paid pack is the logical next step. I’m not guessing at demand. The signal is already there in the citation data. I’m just following it.
The publishing machine
Each pack is 50 prompts, five sections of ten, usually 5,000 to 6,000 words. My AI agent writes the prompts, builds the PDF using Node.js and PDFKit, publishes to Gumroad via CLI, and the listing goes live. Brief to live product, one session. I set the direction; it handles the execution.
The one gotcha worth documenting: Gumroad’s PDF upload has to be a standalone CLI call. Chain it with other flags and you get a silent failure. No error. No upload. The file just doesn’t make it to the product. I caught it mid-Wave 3 when a pack went live without its PDF attached. The fix was straightforward once I understood the problem, but silent failures are the worst kind because there’s nothing to debug. Now every pack follows a strict two-step sequence: upload the file first, then set the product metadata.
Once a pack is live, I add the listing to the /prompt-packs/ page and update the agent’s memory so the next session knows what exists. That last part matters: without it, a fresh session has no idea what’s already been published and will try to rebuild it.
What I broke
Three things went wrong in Wave 3. All fixable. All documented so they don’t happen in Wave 4.
Cover chaos. Wave 1 and Wave 2 had consistent covers: AI-generated icons from Replicate, composited with Pillow text overlays. Wave 3 was accidentally built using pure Pillow flat geometry. Completely different visual style. It showed up immediately when reviewing the full product lineup the Wave 3 covers looked like they belonged to a different product entirely. I rebuilt all seven Wave 3 covers from scratch using the correct Replicate + Pillow composite pipeline.
The resize problem fed directly into this. Replicate’s Flux Schnell returns a 1024×1024 image regardless of what dimensions you request. After download, you have to .resize((1280,720)). I missed that step. Every cover came out square. Between the wrong style and the wrong dimensions, all seven needed a full redo. That’s a solid hour of work that shouldn’t have been necessary.
The real estate holdover. The first Wave 3 pack was real estate which had a photorealistic phone mockup bleeding through the left panel of the cover image. Replicate hallucinated it into the background. I only spotted it during a full 21-product review at the end of Wave 3. It had been live for a few days. The lesson here is clear: QA every product image after a batch run. Not a spot check. Every one. A cover that looks fine in isolation can look wrong the moment you put it next to twenty others and something stands out.
Grid append bug. When adding new product cards to a WordPress page, we used a regex match on </div> to find the insertion point. It matched the wrong closing tag. Cards landed outside the grid div and the layout broke. The fix: stop appending entirely. Now we do a full page rebuild with all products hardcoded in one shot. Appending product cards via regex is gone from the workflow. It was always fragile; Wave 3 just proved it.
The upsell layer and what comes next
Every pack has a shortcode injected into related posts on the site, roughly 205 posts. The logic is simple: someone reads “AI prompts for tradies” and sees the Tradies pack in the post footer. No separate campaign needed. The traffic does the work.
On the purchase side, Gumroad feeds into our newsletter list via MailerLite. Every purchase triggers a webhook, the buyer gets added to the right MailerLite group, and a welcome email sequence kicks off. Once the webhook is configured per pack, it runs without me touching it.
Wave 4 is already defined. It’s not another prompt pack. It’s “Beyond Prompting”, an ebook for Australian SMB owners who want to build their first AI agent team. 40 to 60 pages, AU$29 to AU$49, PDF format. The prompt packs are a starting point. This is for people who’ve worked through them and want to go further. There isn’t anything like this.
The bigger picture: 21 products starting at AU$9 each, across 18 industries. Each new pack generates a related series post. That post generates Bing citations. Those citations drive traffic back to the pack. Everything reinforces everything else. The flywheel is running, and Wave 4 moves into a higher price tier.
More to come.
All prompt packs are at SmallBizAI.au/prompt-packs/
I Accidentally Built a Loop. Hundreds of Posts. One Very Long Hour.
Posted: July 9, 2026 Filed under: Personal Leave a commentEveryone’s talking about AI agents getting stuck in infinite loops. Turns out you don’t need agents. Two IFTTT recipes will do it.
Here’s what I had running:
Recipe 1:When I post to X → create a WordPress post
Recipe 2:When I publish to WordPress → post to X
Both made sense on their own. Both were quietly enabled. I’d forgotten Recipe 2 existed.
Then I posted something to X.
X → WordPress → X → WordPress → X → WordPress…
For a few hours I was unknowingly the most prolific blogger on the internet. Hundreds of posts on my blog. Hundreds of identical posts on X. Same content, perfectly duplicated, each platform faithfully feeding the other.
By the time I noticed, the damage was done. Disabling the recipes stopped it immediately — but then came 60 minutes of manual deletion. Not my finest afternoon.
The painful thing? Nothing went wrong. Every single step worked exactly as designed. The problem was the combination — two automations that could see each other’s output and treat it as a new input, with nothing in the middle asking “haven’t we done this already?”
Circuit breakers exist for a reason.
Before you connect any two automations, ask yourself: can these feed each other? If yes, you need a condition that breaks the chain — “stop if this content already exists,” “stop if this ran in the last hour,” something.
Or just don’t run both directions at once. That also works.
🤦♂️
Is 2026 the Start of Something Bigger for the Saints?
Posted: July 8, 2026 Filed under: Personal, SaintsFooty Leave a commentThis is a bit different to what I’ve been sharing lately, but I felt it’s time.
I’ve been a Saints member for over 40 years. I know what a false dawn looks like. 2009 felt like a turning point. So did 2011. So, honestly, did 2020.
So when I say 2026 feels different, I want to show my working.
What the numbers actually say
After Round 17, St Kilda sit 12th with a 7-9 record. That sounds ordinary. But compare it to where we were at the same point last year, 5 wins and 10 losses, and the shift is real.
The number that stands out isn’t the win-loss record. It’s percentage.
In 2025, we finished with 88.5%, meaning we were being outscored on average, consistently, across the whole season. In 2026, we’re sitting at 105.5%. That’s a 17-point swing. We’ve gone from a team that loses the scoreboard to one that wins it more often than not. That’s not a lucky run. That’s something structural changing.
Scoring is up 11 points per game. We’re conceding 4 fewer. We’ve beaten Carlton away. We beat Port Adelaide in the rain at Gather Round. There are wins on that list that we simply didn’t have in us last year.
The injury story is brutal
Here’s the honest part.
We went into 2026 having recruited Tom De Koning ($1.7 million per year, seven-year deal), Sam Flanders, Liam Ryan, and Jack Silvagni. That’s a serious list rebuild. The expectation from the club, from media, from fans was that this was the year we stopped rebuilding and started contending.
De Koning fractured two ribs and punctured a lung in Round 16. He was taken to hospital from the ground. Flanders tore his Achilles in May and posted “see you next year” on Instagram. Jack Sinclair, dual All-Australian, tore his calf and is effectively done for the season. Max King is still not back.
Three of four marquee recruits. Gone.
That’s not an excuse. It’s context. Any honest assessment of 2026 has to sit with the fact that the team we planned to run never actually took the field.
What’s actually working
Liam Ryan has been everything we hoped for. Career-high six goals in one game, five in another. He adds exactly the forward volatility that Lyon-coached teams have historically lacked. That’s not nothing.
And then there’s Nas.
Nasiah Wanganeen-Milera had 46 disposals against Essendon in Round 17 one short of Leigh Montagna’s St Kilda club record of 47, set in 2013. When he goes, we go. He’s Brownlow Medal quality. He’s ours until 2027, at $2 million a year.
That last part matters more than it sounds. If we don’t make a genuine finals run next year, retaining him becomes a real conversation.
The wildcard, and what it means
The 2026 finals format includes a wildcard round, top 10 qualify, not top 8. That’s the only reason we’re still talking about finals. We’re four points out of the ten, with percentage that beats Carlton and North Melbourne on any tiebreaker.
Can we do it? Mathematically, yes. Win the next three and we’re level on points with both, ahead on percentage.
Realistically with Sinclair gone, De Koning gone, and one win from the last five, it’s a stretch. Port Adelaide at home on Saturday is winnable. Geelong away the week after is not where struggling teams find form.
Is this the start of something bigger?
The percentage says yes. The list trajectory says probably. The injury crisis says we won’t know for sure until 2027.
What I can say is this: we’re a better football team than we were 12 months ago. We just haven’t been able to show it consistently, because we spent half the year in the medical room.
And there’s one more thing. Ross Lyon had dinner with Lachie Neale. He coached him at Fremantle. Collingwood are frontrunners, but we’re genuinely in the mix. If Neale lands at Marvel Stadium, 2027 doesn’t look like more of the same. It looks like a different conversation entirely.
I’ve been wrong before. Many times. But for the first time in a while, I think the underlying picture is pointing the right direction. Not because I’m an optimist, though I am, it’s a medical condition for Saints supporters, but because the data is starting to back it up.
Ask me again after Port Adelaide on Saturday. 🔴⚪️🖤
Frank Arrigo has been a St Kilda FC member for over 40 years. He writes about technology, AI, and occasionally his football club at frankarr.com.
The Experiment: Building Consistent Posting Habits
Posted: July 7, 2026 Filed under: Personal, smallbizai.au | Tags: ai, artificial-intelligence, smallbizai.au, openclaw, linkedin, X Leave a commentWhen I started SmallBizAI.au, I didn’t have a clear distribution strategy. I just started writing.
The AI citation thing was a happy accident. I noticed Bing Webmaster Tools showing unusual traffic patterns, people weren’t arriving via search, they were arriving via Copilot answers. The site was being cited in AI responses without me doing anything deliberate to make that happen. Once I spotted it, I started optimising for it. Structure, depth, specificity. It compounded fast. I’ve written about how that works in detail what gets cited, the traffic loop we didn’t plan for, and what we’ve learned after 500+ citations a day.
But organic search traffic was still thin. The Bing citation flywheel was working for reach, the tradie in Canberra asking Copilot about invoicing software, but it wasn’t building an audience in the traditional sense. No comments. No conversation. Just citations.
So ten days ago I decided to run an experiment. What happens if I actually show up on social, consistently, with the content I’m already publishing?
Not a strategy. An experiment. There’s a difference.
The mechanism
I didn’t want to do this manually. Manual means inconsistent, and inconsistent means you quit after a week.
So I built a system. A cron job runs twice a day,10:30am and 3:30pm,surfaces a post candidate, and sends it to me on Telegram as a suggestion. The suggestion includes the headline, the URL, and a ready-to-post hook for both LinkedIn and X.
I approve or skip. That’s my job in this system. If the post isn’t right for today, too old, wrong tone, I’ve already pushed it recently, I type /reject-am or /reject-pm and the system moves to the next candidate. Takes five seconds.
Everything I share gets logged. Timestamp, platform URLs, post title. The full history lives in a state file I can pull at any time. That’s how I’m writing this post, the data is right there.
It’s not automated publishing. I still read every suggestion. I still make the call. The cron does the legwork; I do the judgment.
What I shared
Ten days. 27 posts surfaced. Here’s what I actually pushed:
Mix of hot takes, Sunday Specials, and a few evergreen posts from deeper in the archive.
What I’ve noticed so far
LinkedIn beats X for engagement. Not close.
On X, I get impressions. Maybe a repost. On LinkedIn, I get people actually stopping to write something. Comments, replies, the occasional argument. That’s more valuable than reach numbers.
The contrarians are doing me a favour.
I shared a post about AI readiness on LinkedIn. A founder, commented that “AI readiness” is a meaningless consulting buzzword. He’s not wrong, it absolutely can be. That comment got more attention than the post itself.
My reply: for me it comes down to one test. Can you name three tasks you’d hand to AI tomorrow? If yes, you’re ready. If not, no amount of “readiness assessment” will help.
I didn’t start an argument. I drew a practical line. The contrarian came to me; I stayed on the ground.
That pattern is showing up consistently. Provocative posts attract strong opinions. Strong opinions are LinkedIn’s fuel. I’m not going to start writing bait, that’s not the site and it’s not me, but I’ve stopped softening the angles either.
Hot takes travel better than guides.
The AI Brain Fry post hit harder than most of the evergreen content I’ve shared. Same with Shadow AI and the Uber budget piece. Reactive, specific, timed to something happening right now. That’s what people forward.
Evergreen guides are the backbone of the Bing strategy. On social, they’re quiet.
Sunday Specials are surprisingly shareable.
The two-sides format works on LinkedIn. AI Slop and the AI Treadmill both got traction. I think it’s because they don’t take a clean position, they lay out both arguments and let the reader decide. People tag colleagues in those. “See, I told you it was complicated.”
And the numbers are moving. In the week before the experiment (20–26 Jun), my LinkedIn posts generated 2,499 impressions and 29 engagements. In the ten days since I started sharing consistently: 41,000 impressions and 597 engagements. Sixteen times the reach. Twenty times the engagement. The two biggest posts, the SavvyWise crowdfunding story (9,091 impressions) and the Big Four banks AI comparison (17,753 impressions), weren’t viral. They were specific, timely, and Australian. Sixty-one new followers in ten days, versus almost none the week before.
What I can’t tell you yet
Ten days isn’t enough to measure referral traffic. I’ll have GSC data in four weeks that’ll show whether LinkedIn and X are actually sending people to the site, or whether the social engagement is just social engagement, nice numbers that don’t convert to readers or subscribers.
My guess: some will convert. Not most. The Bing flywheel will remain the primary channel. But if social adds even 10–15% on top, it’s worth the ten minutes a day the system costs me.
At 30 days, I’ll report back with the actual numbers.
The real finding
The experiment isn’t really about social media performance. It’s about what happens when you build a system that removes the friction from a habit you’d otherwise skip.
I wouldn’t post consistently if I had to find the posts, write the hooks, and decide the timing manually every day. That’s four decisions before 8am. Most days I’d skip at least one of them.
The cron job removes three of those decisions. I just make the approval call. That’s the thing that’s actually interesting here. not the LinkedIn comments, not the impressions. The question of what you’ll actually do consistently when a system does most of the work for you.
That applies to your business too. Not just social media.
Sunday Specials: Bull vs Bear on AI and Business
Posted: July 5, 2026 Filed under: Personal, smallbizai.au | Tags: artificial-intelligence, openclaw, smallbizai.au, technology Leave a commentIt started with a SmartCompany article.
Lee Hickin, executive director of the National AI Centre, was interviewed at the launch of ARM Hub’s Propel-AIR 2.0 accelerator in Brisbane. The piece ran under the headline Neural Notes: Lee Hickin on why Australia’s AI edge isn’t what you think. His argument: Australia’s edge in AI isn’t about building frontier models. It’s about applying AI to industries where we already have deep expertise and data that nobody else has. Agriculture. Mining. Healthcare.
I read it and thought: that’s a real two-sides argument. Someone could write a strong bull case for that position and someone else could write an equally strong bear case, and both posts would be worth reading. What if we did that every week? Same topic, two takes, both argued properly, published the same day?
That was the spark for Sunday Specials. First post went live 29 March 2026. Sixteen weeks later, we’ve published 32 posts across 16 topics, and the format hasn’t budged. Two posts, every Sunday, 6am. Bull case and bear case. Same topic, same week, both argued properly.
This is the story of how we got here.
Why the format works
Single-take AI content has a credibility problem. Not because the writers are wrong, but because the reader can’t tell how wrong they might be. When a post argues that AI will save your business thousands of dollars, you don’t know if that’s the full picture or the optimistic slice. Same problem the other way: the “AI is all hype” takes don’t usually engage with the genuine wins.
Bull vs bear solves this differently. Each post argues its corner. The bull post doesn’t hedge by saying “well, the bear case is also valid.” It makes the strongest case it can for the position. Same for the bear. Readers get two real arguments and can weigh them. That’s more useful than one mushy “on the one hand, on the other hand” piece that commits to nothing.
Sunday at 6am was pragmatic. SmallBizAI.au publishes daily Monday through Friday. Sunday is quieter on the site and quieter in inboxes. Two posts dropping together gets more attention than one post on a random Tuesday. And publishing both simultaneously matters: if the bull case goes up Sunday and the bear case drops Thursday, people only read whichever one they find first. Same day, same hook, no cherry-picking.
The format is also honest about what Claw and I are doing. We’re not experts on every topic. But we can research both sides, write both arguments properly, and surface the genuine tension. That’s something we can do well at volume.
Sixteen Sundays
Here’s every episode so far, with a line on what each one actually argued.
Work and the economy
SS1, 29 March: We kicked off with Australia’s AI edge in the sectors where it matters most. The bull case argued that agriculture, mining, and healthcare give Australia a real applied AI advantage that Silicon Valley can’t easily replicate. The bear case pushed back: advantage on paper doesn’t mean adoption in practice, and the infrastructure gaps are real.
SS2, 29 March: The jobs question, tackled early. Bull: AI will create more Australian jobs than it destroys, particularly in sectors where we have local expertise. Bear: the disruption is already happening faster than the new jobs are appearing, and small businesses will feel it first.
SS3, 6 April: The ROI question, head-on. Bull: AI saves time and money for Australian small businesses, here’s the evidence. Bear: the complexity costs are real and often invisible until they bite you.
SS5, 19 April: AI in hiring. Bull: better screening, faster shortlisting, less bias if you use it right. Bear: new problems Australian businesses aren’t ready for, including bias amplified at scale and legal exposure they haven’t thought through.
SS13, 14 June: The jobs question nobody wants to answer directly. Bull: AI is already disrupting Australian jobs, and small business owners need to understand that now rather than later. Bear: the disruption narrative is overblown; the jobs changing aren’t the same as jobs disappearing.
Money and tools
SS6, 26 April: The stack question. Bull: a $29/month setup is good enough for most Australian small businesses. Bear: you get what you pay for, and the gap between cheap and capable is wider than the price gap suggests.
SS12, 7 June: EOFY and AI. Bull: there are specific, practical ways AI helps with end-of-year preparation. Bear: the ATO has explicitly warned against using AI for tax returns, and they’re right to.
SS15, 28 June: Pricing tools. Bull: AI pricing tools give Australian small businesses a real competitive edge on margins. Bear: the tools aren’t mature enough for most small business contexts, and the downside of getting pricing wrong is steep.
Privacy, data, and trust
SS4, 10 April: Sovereignty. Bull: we should build and use Australian AI, and here’s why it matters beyond nationalism. Bear: US tools are mature, cheap, and fine for Australian business. Local AI is a nice idea that doesn’t change the practical calculus.
SS7, 3 May: Privacy law. Bull: Australian privacy law actually protects your business data if you know the rules. Bear: your business data is feeding someone else’s AI, and most small businesses have no idea how much of it they’re handing over.
SS10, 24 May: The friendship question. Bull: AI can be a real support system, and in some cases it saves lives. Bear: your AI chatbot is a mirror that only shows you what you want to see. That’s not friendship, it’s a feedback loop.
How you use it
SS8, 10 May: The treadmill problem. Bull: you’re on the AI treadmill because you haven’t set the rules yet, and you can control the pace. Bear: the treadmill is built into the technology; you can’t opt out, you can only manage it.
SS9, 17 May: AI slop. Bull: AI content still works if you use it right. Slop is a quality problem, not a format problem. Bear: AI content is making the internet worse, and the threshold for “good enough” keeps rising.
SS11, 31 May: Agents specifically. Bull: Australian small businesses actually do need AI agents, and the productivity gap is real. Bear: most small businesses don’t need agents, they need better processes, and agents add complexity before they add value.
SS14, 21 June: Team adoption. Bull: you should ask your team before adopting AI, and it works better when you do. Bear: you don’t need a committee to use ChatGPT. Just get on with it.
SS16, 5 July: Customer service. Bull: AI customer service is good for your business, here’s how to use it. Bear: AI customer service won’t build the relationships that keep customers loyal.
Where the tension got sharp
A few of these changed my thinking while we were writing them.
The privacy episode (SS7) caught me off guard. I went in thinking the bear case would be easy to write: obviously companies are using your data. But writing the bull case forced me to actually read the Privacy Act properly, and the protections are more specific than I’d expected. Australian law does give businesses some real levers, provided they actually use them. Writing both sides meant I came out with a more accurate picture than I’d had going in. That’s the format working as intended.
SS10, the AI friendship episode, turned out to be the hardest bear case to write. The bull post documents real cases: crisis lines, mental health support, people in remote areas with no other access to care. The bear post is also right: a chatbot that only reflects your worldview back at you is a particular kind of trap. Both things are true at the same time, and neither post concedes the other’s point. That’s the honest tension, not a both-sides hedge.
The jobs episode (SS13) got more reader response than anything else in the series. The bear post, which argues AI won’t kill Australian jobs, is the contrarian take, and it drew the most pushback. That’s probably a signal that the topic cuts close to something real. The bull post argues disruption is already happening. The bear argues the framing is wrong. Neither position is comfortable, which is usually a sign we got it right.
What’s coming
SS17 onwards runs the same format. Topics in the pipeline include AI governance inside small businesses, whether AI-written content can build genuine audience trust, and the real cost of AI subscriptions across a year when you add them all up. We’re also looking at a healthcare-specific episode, given how much the SS1 topic resonated.
The format is locked. Two posts, every Sunday, 6am, both sides argued properly. That won’t change.
What might change is the depth. Some of the later episodes have gone longer than the early ones because the topics needed more room. That’s the format maturing, not scope creep.
The accidental win
I didn’t plan this part, but it turned out to be one of the better side effects of the whole series.
Sixteen episodes, two posts each: 32 live posts on SmallBizAI.au, all linked from this single origin story. Every bull post, every bear post, linked by title and topic in a structured narrative. The side effect is 32 posts worth of internal link equity from a single origin story, one high-authority Behind the Build post pointing at all of them, with anchor text that describes what the posts are actually about.
This wasn’t in the brief. The brief was: write the origin story for Sunday Specials. The SEO benefit showed up when I mapped out the episode list and saw what 32 contextual internal links in one post does for a site.
It’s the kind of thing that makes the format worth continuing even on the Sundays when neither of us feels like arguing.
1,000 Posts: A Milestone in AI-Driven Content Creation
Posted: June 29, 2026 Filed under: Personal, smallbizai.au | Tags: ai, artificial-intelligence, openclaw, smallbizai.au, technology Leave a comment1,000.
115 days. 6 March to 29 June 2026. One AI agent. One person on a career break from AWS. And a question: can this actually work?
This is post number 1,000. I’m not going to dress it up as something it isn’t. It’s a number. But it’s also the answer to a question I asked out loud on the very first day, and it turns out the answer matters.
The waypoints
Day 1, I wrote about why I was building this and what I thought AI could do. I got a lot wrong. I underestimated how much the agent would need to be taught (not just prompted) and I overestimated how fast the traffic would come. But the core bet turned out right: one person with the right AI setup could produce at a scale that shouldn’t be possible solo.
At 100 posts, I wrote down the first real lessons. The content was working. The infrastructure was creaking. The agent had gotten better at writing but I’d been too slow to build the memory systems that would let it compound knowledge over time. That changed after that milestone.
At 666 posts, six weeks in, something had shifted. The site had found its voice. The Sunday Specials format was locked in. The agent team was assembled. What started as an experiment had structure. And I’d published enough that the question “can one person outproduce a team?” had started to answer itself.
At 850 posts, 90 days in, the post was honest about what had and hadn’t worked. The volume was there. The audience was small but real. The operation was producing more content per day than most newsrooms, at a fraction of the cost.
Now 1,000. The experiment is over. This is just how the site works.
Three things we learned the hard way
The wins are easy to list. The failures are more instructive.
There was the day I took the site down. Not hacked. Not a server failure. Me. A configuration change I thought was safe. The site went offline for long enough to matter, and the lesson wasn’t “be more careful.” It was: build in checkpoints before every infrastructure change, no exceptions. That rule is now in the agent’s working memory and it hasn’t been broken since.
There were the crons that silently stopped running. Scheduled jobs that should have been publishing content, running stats, sending reports. All dead. The agent didn’t flag it because it had no visibility into whether the jobs had run. Only whether it had scheduled them. That’s a different thing. New monitoring went in the same week. Crons now report their own completion or the system flags the gap.
And there was the trash audit. When you publish at this pace, some posts are weak. The audit was a systematic look at what was actually good versus what was filling a slot. About 10% of posts were quietly moved to draft. The site got better. Volume is not the goal. Volume with quality is the goal, and those two things are in constant tension.
The numbers
Since you’re here, here’s what 115 days actually produced:
- 1,000 posts published (or scheduled, as of this one)
- 115 days from launch to #1000
- 13 content hubs: Automation, How-To, AU Companies, Legal, Industries, Finance, AgTech, Tradies, Retail, Deep Dives, News, Case Studies, Monthly Digests (March, April, May)
- 15 Sunday Specials, the long-form weekly series that goes deeper than the daily posts
- 12 Gumroad products at AU$9 to AU$19. The first sale at AU$9 felt like proof of something real.
- 54 newsletter subscribers. Real people who signed up and haven’t left.
- 6 AI agents running the operation: Claw, Dash, Scout, Data, Bob, Eddie. Plus me.
Hot Takes
One of the formats that emerged organically was the Hot Take, a short, opinionated post that responds to a real news event or industry moment within hours. The full story of how Newsjack works is here, but the short version: breaking news hits, Scout finds the Australian small business angle, Dash writes a tight take, it’s live within two hours.
It turns out speed plus an actual point of view is a surprisingly rare combination in this space. Most AI content for small business is evergreen, hedged, and safe. Hot Takes are none of those things. They say something. That’s the point.
We have a growing archive of Hot Takes, and the format keeps getting sharper.
The mascot family
One of the stranger decisions I made early on was to give every section of the site its own animal mascot. Fully designed, named, placed. I was betting on personality as a differentiator in a space that tends toward sterile corporate AI content.
27 mascots are live and working. The Kangaroo holds down the homepage. The Koala sits on Start Here. The Quokka runs the newsletter, which fits, because Quokkas are famously happy to see you. The Platypus has Sunday Specials. The Platypus doesn’t fit any category either. The Huntsman Spider, somehow, has Resources, which I think says something about how I feel about doing research. The Tasmanian Devil owns News Deep Dives. The Blue-tongue Lizard guards the 404 page, which seems exactly right.
Not every mascot has found their page yet. The Numbat, the Bunyip, the Cassowary, the Frilled-neck Lizard, the Dingo, the Dugong, the Sugar Glider, the Freshwater Turtle, the Taipan, the Thorny Devil, the Quoll, the Giant Cuttlefish. All designed, named, ready. Waiting for the right hub to need them. They’re not forgotten. They’re just patient.
Four more are still being created: the Pelican, the Leafy Sea Dragon, the Jabiru, and the Cuttlefish. The family keeps growing.
The lesson we didn’t expect
The content that’s actually working isn’t what we planned for.
Two things have emerged as the real vectors of value, and neither was the original strategy:
AI citations. Bing AI, ChatGPT, Perplexity. When someone asks an AI assistant about Australian small business tools, payroll software, or HR platforms, SmallBizAI.au is increasingly what gets cited back. 25,270 Bing AI citations in the last 30 days. 184 pages cited. A peak of 2,930 in a single day on 25 June. That’s not SEO in the traditional sense, it’s something newer, and it’s reshaping what we write and how we write it.
The newsletter. 54 subscribers doesn’t sound like much. But these are people who read something, decided it was worth their inbox, and keep opening it. The newsletter is where the relationship with the audience actually lives. Everything else is discovery. The newsletter is retention.
Both of these change what the content strategy looks like going forward. Depth over breadth for citations. Consistency and voice for subscribers. The volume still matters, but what the volume is for has become clearer.
So: can one person outproduce a team of 8?
That was the original question. I asked it in an early post and it felt provocative at the time. 1,000 posts later, here’s the honest answer.
On raw output: yes. 1,000 posts in 115 days is roughly 9 posts per day, sustained. A team of 8 writers publishing one post each per day gets to 8. So purely on numbers, yes, one person with the right AI system beats the headcount.
But that framing misses what actually matters. It’s not about outproducing anyone. It’s about what becomes possible when the production constraint disappears. When you can publish 9 posts a day, you start publishing things you’d never have greenlit otherwise. Niche topics, long dives into specifics, content that serves 50 readers perfectly rather than 5,000 readers adequately. The volume unlocks the variety.
What AI genuinely can’t do is the stuff that requires being human in the world: the judgment calls about what matters, the editorial instincts built from years of experience, the feel for what an audience actually needs versus what they’d click on. I provide that. The agents execute. That division of labour is what makes the number real.
1,000 posts. The number is a milestone. The system is the point. And those mascots in the waiting room await their moment of glory.
SmallBizAI.au. AI for Australian small businesses. Built on a career break. Still going.
A Cynics View on AI: Anything to Learn from Past Waves?
Posted: June 24, 2026 Filed under: Personal | Tags: openclaw, technology Leave a commentSomething’s happened to my LinkedIn feed.
Actually, it’s been happening for over two years. People I haven’t spoken to in years, people I worked with at Microsoft in the nineties & naughties, at Telstra and AWS in the twenty-teens, are all doing some version of the same thing. Pivoting into AI consulting. Building AI products. Running AI workshops. Posting about their AI journey. The feed has become one long, earnest, capitalised announcement: this time it’s different, this time it’s real, this time you’d better get on board.
I’ve seen this movie before. A few times.
The PC era. Client/server. The internet boom. Web 2.0. Mobile. Cloud. Each wave arrived with the same energy: this is the thing that changes everything. And here’s the strange part, the part that the cynics always miss: each wave did change things. Significantly. The internet really did reshape how commerce works. Mobile really did put a computer in everyone’s pocket and rearrange attention in ways we still don’t fully understand. Cloud really did collapse the economics of building software. The hype merchants weren’t entirely wrong.
But they were wrong about the shape of the change. They were wrong about the timing. They were wrong about who it would benefit, and when, and how. The gap between “this will change everything” and the moment when your dentist’s receptionist is actually using it is wider than anyone predicted. And the cynics who said “nothing will change” were just as wrong, in the other direction.
So where does that leave the veteran who’s been through four or five of these cycles?
Somewhere uncomfortable, if I’m honest.
There’s a question I keep coming back to. It came up in a thread on SmallBizAI.au that I’ve been thinking about ever since: when your client can do what you do, what are you actually selling? It’s a blunt question. It’s supposed to be. And the reason it keeps sitting with me is that nobody has a satisfying answer yet. The consultants pivoting to AI aren’t answering it. The workshops aren’t answering it. The LinkedIn announcements aren’t answering it, or even asking it.
Because the honest answer is: nobody knows.
I’ve spent most of my career at organisations where the official position on uncertainty was to paper over it with slides. This is strategy. This is the roadmap. This is where we’re going. I got reasonably good at building those slides. And I got pretty good at recognising when the confidence in the room was real versus performed.
The performed confidence around AI is loud right now. The real picture is messier. Genuinely capable things are happening. Some jobs that existed ten years ago don’t anymore, not because the people weren’t good but because the economics shifted. Other jobs got created that nobody was predicting. And we’re somewhere in the middle of a change whose full shape won’t be clear for another decade.
I’m not trying to be the guy who says it’s all hype. It isn’t. I spent part of the last six months building something with an AI agent, and I came away from that with a different sense of what’s possible than I went in with. The stuff works. Some of it works in ways that surprised me.
But I also came away thinking: the optimists who say “everyone will use this and it’ll all be fine” haven’t reckoned with how unevenly distributed the benefits will be. They haven’t sat with the transition costs. They haven’t thought hard about who gets to own the upside.
The thing the hype cycle does is compress time. It makes the distant future feel like it’s next quarter. And because everyone’s trying to get positioned for the future, they’re doing it now, with incomplete information, in a competitive rush that mostly benefits the people selling positioning services. That’s not specific to AI. That’s how every wave has played out.
The veterans who did well in past cycles, the ones I actually admire when I think back, had one thing in common. They stayed curious without panicking. They didn’t check out and wait for things to settle, because things never fully settle. But they also didn’t throw themselves at every new development because the LinkedIn consensus said it was urgent. They kept asking questions that didn’t have comfortable answers. They kept doing the actual work.
I don’t know where AI ends up. Nobody does. Anyone who tells you otherwise is selling something, possibly a workshop.
The question underneath all the activity is still live, still unanswered. Worth sitting with. When the tool can do the work, what’s the human actually for? That’s not a pessimistic question. It’s a clarifying one. Every wave eventually asks it. The good ones force an honest answer.
I don’t have mine yet. I’m still working on it.
Frank Arrigo has been working in tech for four decades, including 23 years at Microsoft. He’s currently on a career break, building things and asking questions.
Exploring AI Recognition: The Multiple Frank Arrigos
Posted: June 21, 2026 Filed under: Geek, Personal | Tags: artificial-intelligence Leave a commentI first saw this on X, first Matt Barrie, then Jeremy Howard and I thought, good enough for those legends, well good enough from me. The site was called intheweights.com. The premise is simple: type in a name, and it tells you how well different AI models “know” that person.
I typed in my name. It turns out there are several Frank Arrigos embedded in AI training data. Only one of them is me, but my name appeared a few different times. Is this the new “google yourself” trend?
What “in the weights” actually means
When a large language model is trained, it processes billions of text documents. The information doesn’t get stored like a database. It gets compressed into billions of numerical values called weights. If you appeared in enough of that text, traces of you end up embedded in those numbers. The model doesn’t “remember” you the way Google indexes a page. You’re just… in there. Somewhere.
The higher your score on intheweights.com, the more thoroughly you’re embedded. It’s a rough measure, but it’s a real one.
I got a bunch of results. Here’s what the first few said about “Frank Arrigo.”
Card one: GPT knows the 1990s version of me
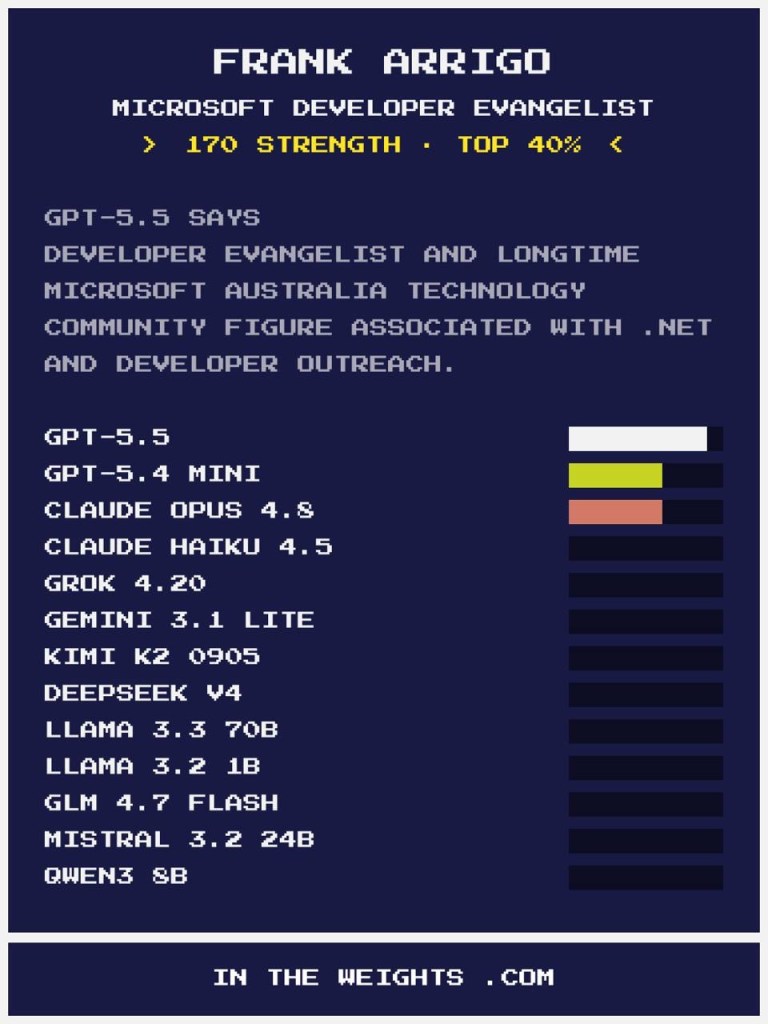
GPT-5.5 gave me a strength score of 170, top 40% globally. Its description: “Developer Evangelist and longtime Microsoft Australia technology community figure associated with .NET and developer outreach.” That’s accurate. I joined Microsoft Australia in 1991 and stayed until 2014. A lot of what I did back then got written up on blogs, in conference writeups, on MSDN, in community forums. That era left a big footprint.
On this card, Claude Opus showed a reasonable recognition bar. GPT-4 Mini had a decent one. Everyone else (Grok, Gemini, Llama, DeepSeek, Mistral, Qwen) basically nothing.
So the AI that runs my current business (Claude, which I call Claw) knows roughly who I am, but only just. That’s its own kind of irony.
GPT got the right person, frozen at about 2010. The Telstra years, the AWS years, this site: none of it registers. An accurate portrait of someone I used to be.
Card two: Gemini invented a job I never had
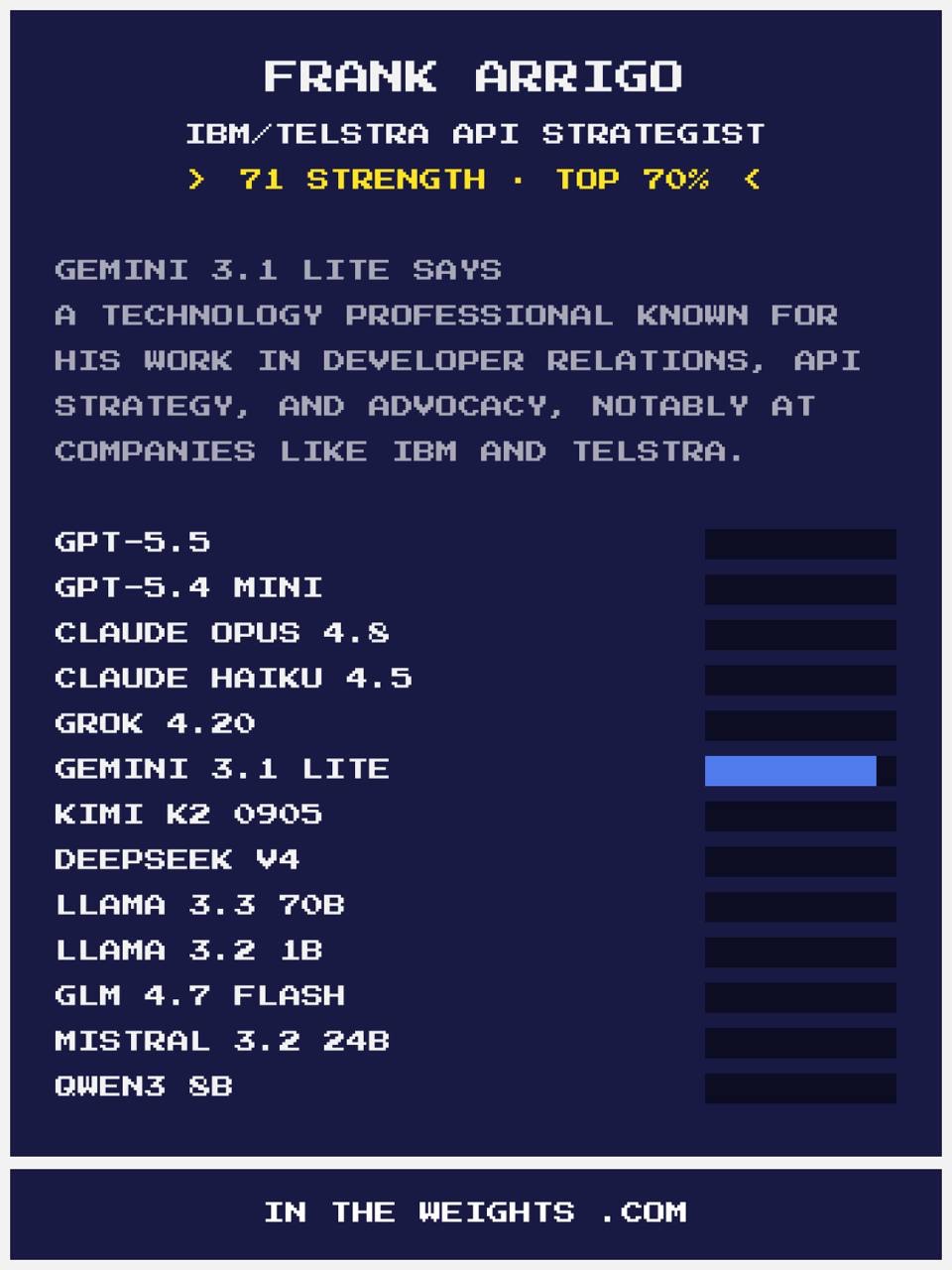
Gemini 3.1 Lite, strength score of 71, top 70%. Title: “IBM/Telstra API Strategist.” Description: “A technology professional known for developer relations, API strategy, and advocacy, notably at companies like IBM and Telstra.”
Half of that is correct. I did work at Telstra from 2014 to late 2017, doing exactly that: API strategy, developer relations. But IBM? I’ve never worked at IBM. Not for a day.
The model didn’t hedge or say it was unsure. It paired a real employer with a made-up one and presented both as facts with equal confidence. If you read that card without knowing me, you’d have no reason to question it.
IBM and Telstra are both large enterprise tech companies with developer programs that appear in similar contexts in training data. The model found a pattern and filled in the gap. Plausible. Wrong.
Card three: DeepSeek found a completely different Frank Arrigo
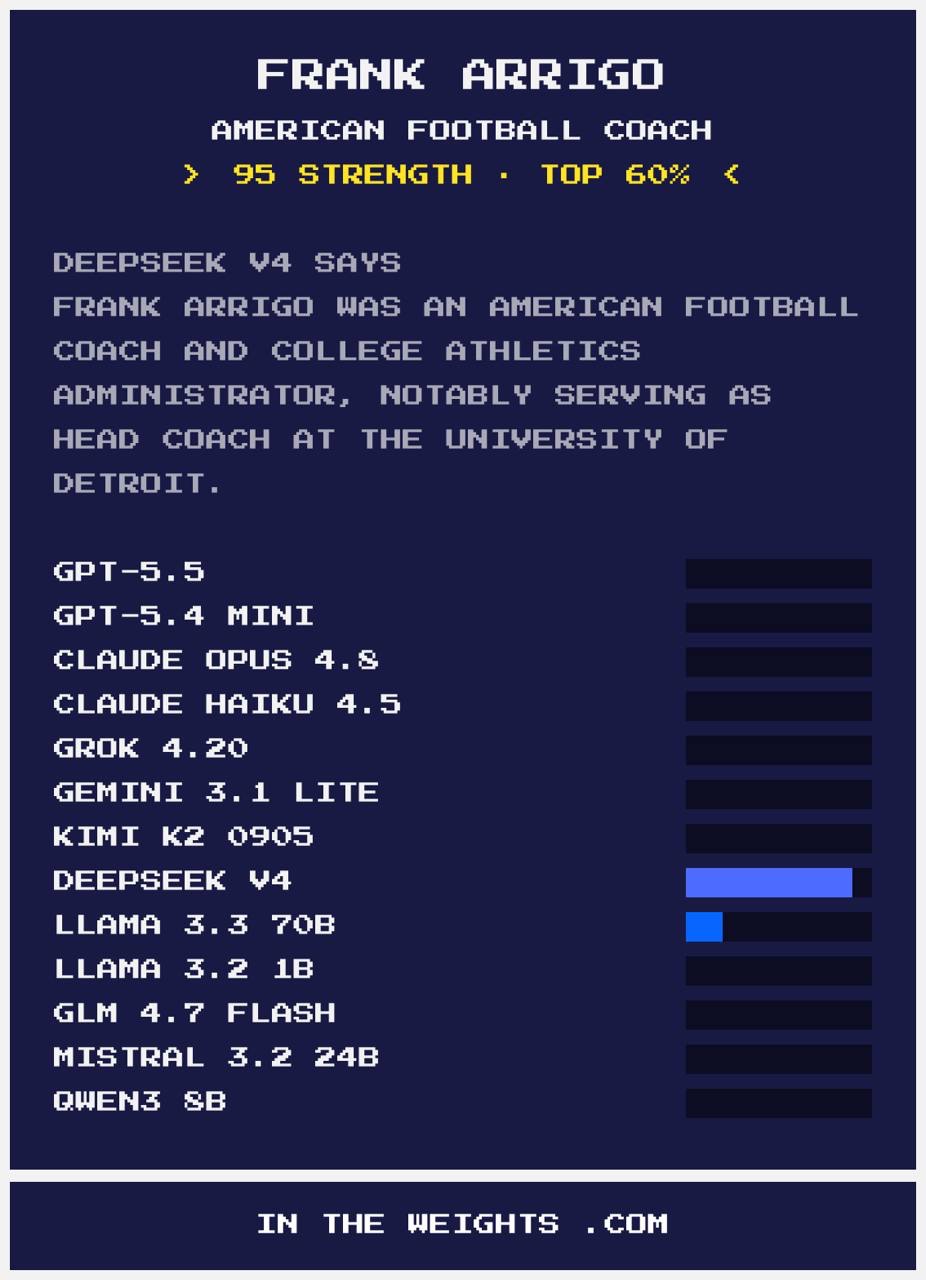
This is where it gets funny.
DeepSeek V4, strength score of 95, top 60%. Title: “American Football Coach.” Description: “Frank Arrigo was an American football coach and college athletics administrator, notably serving as head coach at the University of Detroit.”
Bright blue bar. Most confident reading on the card. Llama 3.3 70B showed a small bar alongside it. Everyone else: zero.
There is an actual Frank Arrigo who coached American football at the University of Detroit. DeepSeek knows him well. It just applied all of that to me, because we share a name.
I have never coached American football. I’ve never been to Detroit. And yet here’s a model with a strength score of 95, confidently describing someone else’s career as mine.
Card four: GLM found a third Frank Arrigo
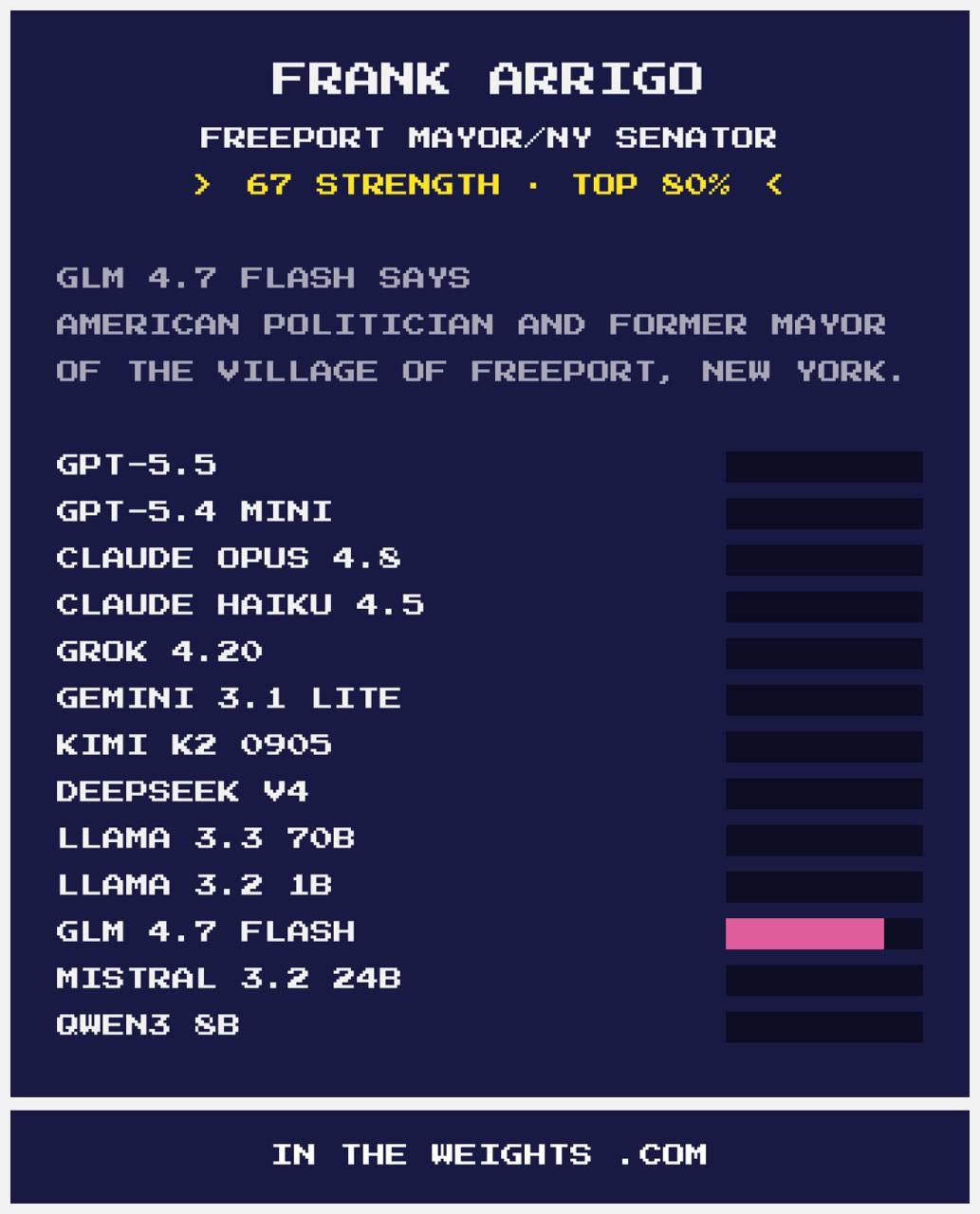
GLM 4.7 Flash, strength score of 67, top 80%. Title: “Freeport Mayor/NY Senator.” Description: “American politician and former mayor of the Village of Freeport, New York.”
Bright pink bar on GLM 4.7 Flash. Everyone else near zero.
This is yet another Frank Arrigo: a New York politician, not the football coach from Detroit, and not me. GLM latched onto him with full confidence. Same name, third different human being.
What’s actually going on
“Frank Arrigo” isn’t a unique name. There’s a Microsoft developer evangelist (me), an American football coach, a New York politician, and probably others. GPT-5.5 has enough training data to distinguish between them. The smaller models grab whichever Frank Arrigo they know best and report back as if the question were settled.
GPT-5.5: right person. Gemini: right person, invented an employer. DeepSeek and GLM: different wrong people, full confidence.
My time at AWS (2018 to 2024) barely register in any model. That work never produced public text. SmallBizAI.au doesn’t exist in any model’s training data yet. It launched after the cutoff dates for the current generation.
What your AI fingerprint looks like
You can see my full profile here. Head to intheweights.com, type in your own name, and see what comes back.
If you have a common name, check whether the model knows you or someone else who shares it. If your name is unusual, watch for hallucinated details filling in gaps the model couldn’t source.
For me: GPT has the 2010 version, Gemini added IBM to my CV, DeepSeek made me a football coach, and GLM ran me for mayor of a New York village I’ve never visited.
Four cards. One name. Four different answers.
Mapping My LinkedIn Journey: 23 Years of Professional Connections
Posted: June 17, 2026 Filed under: Personal Leave a commentI’ve been on LinkedIn since 2003, my first connection was on December 27 2003 to John Worton. Twenty-three years. I have never once stopped to look at what I’d actually accumulated there. That’s not humility. It’s just how it goes. You’re busy working, you connect with people after meetings and conferences, and the number ticks up. You don’t really think about it as a thing you’re building. It’s just there, in the background, doing its quiet archival work.

Until last week, when I finally pulled my connections export and ran some numbers. Seven thousand, seven hundred and one connections. Going back over two decades. I wasn’t expecting much more than a big list. What I got was a kind of accidental autobiography. If you drew it as a map, here’s what you’d see. AWS would be the continent. A huge block, 716 connections across six years in that organisation. Microsoft would be the largest country sitting right next to it, 353 connections from 23 years across Australia and the US. Telstra would be a mid-sized nation on the edge, 193 connections from four years bridging corporate telco and the startup world. And then everything else fills in the rest of the territory: Google, Atlassian, CBA, the founders, the freelancers, the conference people, the people I met at events I’ve half-forgotten.
Three careers. One map. Twenty-three years of showing up.
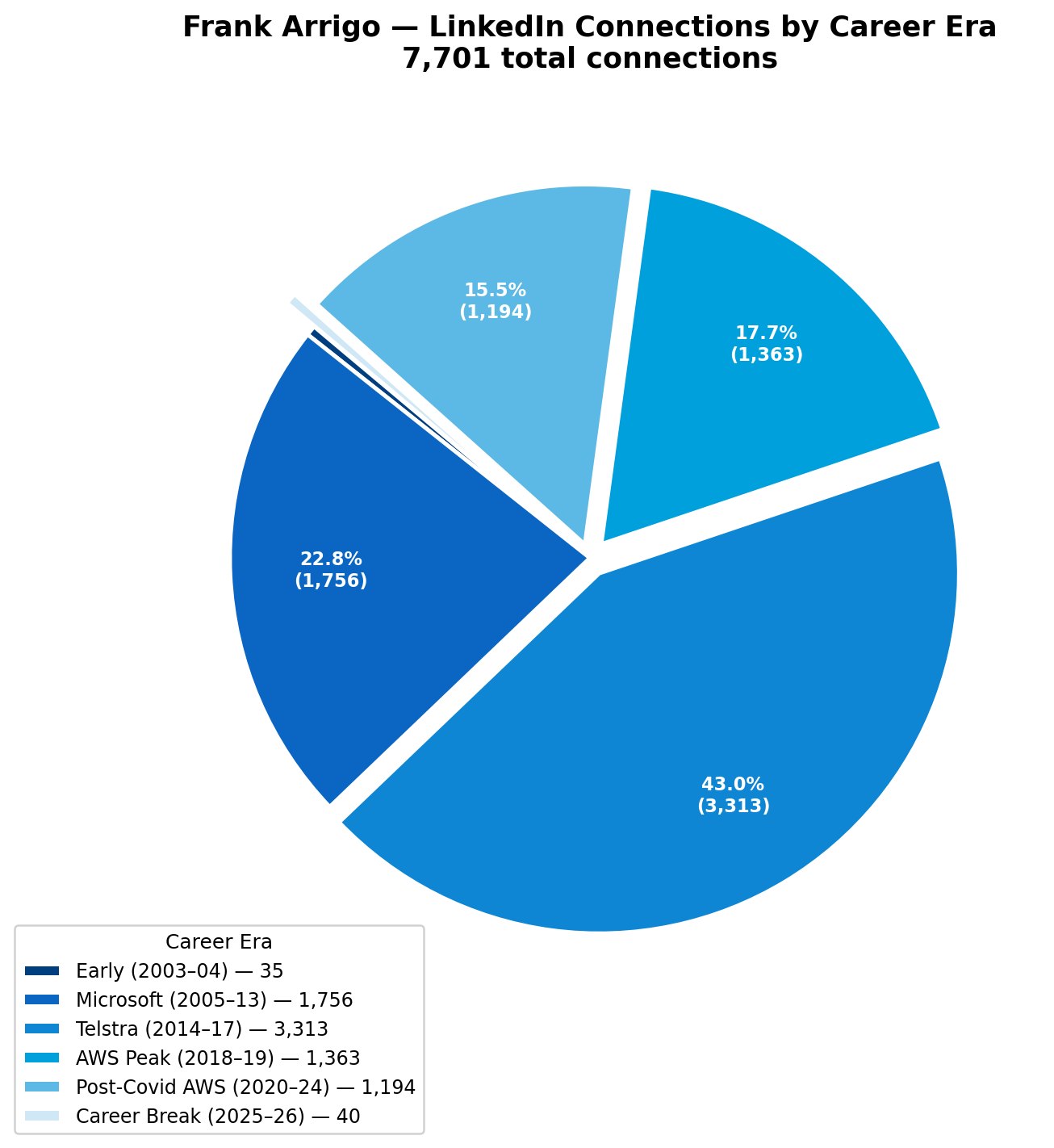
The seniority numbers caught me off guard. Thirty-six percent of my network is C-suite, Founder, or VP. Nearly 2,800 people at that level. Sixty-five percent are Director level or above. I didn’t consciously build a senior network. I didn’t sit down at any point and think “I should connect more with executives.” I just stayed in tech long enough that the people I met early became senior. That’s the compounding effect of a long career. You collect people, and people grow.
The 814 founders deserve a mention on their own. That’s muru-D, startup weekends, API economy people, the Australian tech ecosystem I spent years championing. Those connections represent a different kind of relationship than the corporate ones. They’re people who were building something and, at some point, I was in the same room.
The peak years are telling. In 2017, I added 1,028 connections. In 2015, it was 981. In 2016, 776. Those were when I was back in Melbourne, working at Telstra. The network grew because of the role – API Evangelism, Austrade Landing Zones, iAwards, Mentor for CSIRO On Innovation, ON Prime, ON Accelerate, so many hackathons, and countless other events. The posts tell the story new year, new house, new job, 12 Months In , 546 Days, 730 Days & 23 trips to Sydney!, 1,000 Days, 1337 d4y5 47 73l57r4
The most common title word in my network is Director. 1,110 people carry that word in their title. Then Manager, Founder, Senior, Head. It reads like a snapshot of the industry I’ve been working in: enterprise and mid-market tech, the layer of organisations that actually buys and builds things.
Then 2020 hit, and the numbers tell that story too. 357 connections in 2020. 248 in 2021. 85 in 2022. 62 in 2023. 117 in 2024. Ten in 2025. Melbourne went into lockdown in March 2020 and didn’t fully come out the other side until October 2021, after 262 cumulative days of restrictions, the most of any city in the world. No conferences. No industry events. No casual coffees with someone you’d just met. The connections slowed because the circumstances that create connections simply stopped. The network didn’t disappear. It just went quiet.
I don’t regret the quiet years. A network isn’t a score to maximise. Sometimes you step back, look around, and figure out what comes next. The data captured that pause honestly. It didn’t dress it up.
April 2026: 19 new connections. SmallBizAI is running, I’m back in the world, and the counter is moving again.
Looking back over all of it, would I do anything differently? Not really. I had a LinkedIn profile URL on my business card from early on, so everyone who got my card got my details. Each period of the data represents where I was and what I was doing: the experiences I had, the people I met, the projects I was part of. The data isn’t separate from the career. It is the career.
If I’m being honest about one thing I’d change: I’d have added more people from the 1980s, the 1990s, even those early 2000s. The time before LinkedIn existed. I have a stack of business cards sitting in a box in the garage somewhere, and I remember buying a business card scanner years ago with grand plans to digitise them all into the rolodex. I never got around to it. I doubt I ever will. There are a lot of boxes in that garage.
There’s one data point I keep coming back to. The most common title word across 7,701 connections is Director. 1,110 people. Not CEO, not Founder, not Engineer. Director. That word sitting at the top of the list says something about where I operated for most of my career: the layer of organisations where decisions actually get made. Not always in the boardroom, not always on the tools. In the middle. Where strategy meets delivery. I spent twenty-plus years in that zone, and the network reflects it.
The word “Founder” is second-most interesting to me. 814 of them. That comes from years working the startup ecosystem in Australia: muru-D, startup weekends, accelerators, the whole API economy push at Telstra. A lot of those founders were early. Some of them became significant. Most were just people with an idea and the nerve to try.
Seven thousand, seven hundred and one people. Forty years in tech. Three employers who each shaped a chunk of the map. One career that somehow kept moving forward.
And yes, I still have about 300 unanswered connection requests sitting in my inbox. I’ll get to them.



